
|
・In English
前提知識
・最小二乗法
■誤差関数とは
誤差関数とは、機械学習などにおいて、真値とモデルの推定値との誤差からモデルの精度を評価するための関数で、損失関数とも呼ばれます。
誤差関数には誤差二乗和、交差エントロピー誤差などがあり、この誤差関数から得られた値が小さければ推定値が真値に近いと言えます。
■二乗和誤差
最小二乗法にも使われる考え方で、真値と誤差の差分の二乗を取ります。1/2を乗じている理由は、誤差の最小値を求める際、この関数を微分した時に係数を消去するためです。(後述)

具体例で考えます。人、犬、猫の画像を判別する機械学習があり、今正解は犬の画像であるのに対し、機械学習が推定した確率は以下のとおり、人である可能性が高いと誤って推定しました。
この時、誤差関数値は以下となります。

次に機械学習は推定した確率は以下のとおり、犬である可能性が高いとして正解しました。この時の誤差関数値は小さな値となり、先ほどの例に比べて正解に近づくに従い、値が小さくなるのが解ります。

<誤差関数の最小値>
この誤差関数は二次関数なので、最小値を求めるには関数を微分した結果が0に近づけば良いです。機械学習においては勾配法により最小値を求めていきます。

■平均二乗誤差(MSE:Mean Square Error)
二乗和誤差と形は似ておりますが、この形で損失を計算する方法もあります。

■交差エントロピー誤差(Cross Entropy Loss)
以下式で表すことができます。底は自然対数eです。

先程と同じ例で誤差関数を計算します。機械学習の推定値の誤差が小さい方が、誤差関数の値が小さくります。

<誤差関数の最小値>
対数は以下のようなグラフになりますので、最小値を求めるにはこれも関数を微分した結果が0に近づけばよいです。

<交差エントロピー誤差のメリット>
二乗和誤差と交差エントロピー誤差どちらが良いのでしょうか。結論としては交差エントロピー誤差の方が使われることが多いようです。
先ず誤差関数は、最小値を求めるために微分が容易であることが求められます。その点はどちらも微分が容易なので有意差はありません。
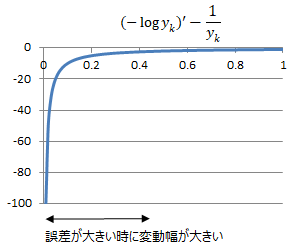
次に微分後の関数の特性について、二乗和誤差の微分は1次特性となっているのに対して、
交差エントロピー誤差の微分は反比例の特性になっており、誤差が大きい程関数の変動が大きいため学習効率が良いというメリットがあります。
これが交差エントロピー誤差が使われる理由となっています。
<Binary Cross Entropy Loss>
上記の交差エントロピー誤差に対し、誤差関数を以下式で表すものをBinary Cross Entropy Lossといいます。pythonの実装例はこちら。

■そもそも何故誤差関数が必要なのか
誤差関数は機械学習の精度を測るために用いるのですが、何故誤差関数が必要なのでしょうか。確かに、テストした結果の正答率を見れば精度は解りますし、
勾配法の際に誤差を小さくするための処置として誤差二乗などを使いますが、誤差二乗の和は必要ありません。
従って誤差関数は必要ないと思うかもしれませんが、実は学習の精度を測るためには重要な役割を持っています。それは、パラメータを変化に対して正答率の変化は鈍い、
あるいは正答率は不連続な値で唐突に変化しうる得るので、パラメータ変化の妥当性を測るのに正答率は実は適さないからです。
サブチャンネルあります。⇒ 何かのお役に立てればと
|
|