
|
前提知識
・1次システムの状態方程式(サーボ問題①)
・Scilabの使い方
こちらで1次システムのサーボ系の状態フィードバックの仕方について説明しました。
しかそこで説明したのはロバスト性の低い手法でしたので、ここでロバスト性を高める手法について説明します。
■内部モデル原理とは
ここで内部モデル原理という手法を用います。内部モデル原理の説明は別途しますが、まずは形を説明します。
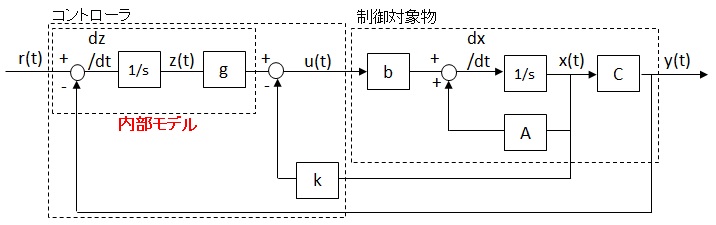
上記システムの微分方程式は以下のとおり。
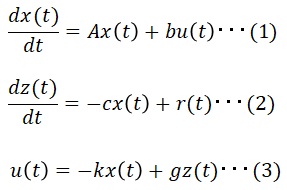
上記式を状態方程式で表現します。
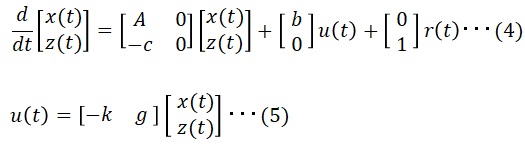
■フィードバックゲインの求め方
考え方はこちらでも説明したとおり極配置法を使います。すなわちフィードバックシステムの特性方程式の根が
安定(根が負)になるようにゲインを設定すればいいのです。
それでは具体的に求めていきます。(5)を(4)に代入します。
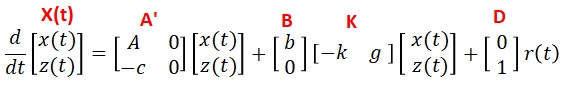
上記の赤文字の様に変数を代入し、ラプラス変換します。ラプラス変換の仕方はこちらで説明。
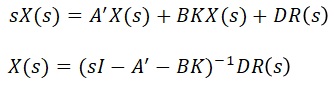
上式の特性方程式は以下のとおり。
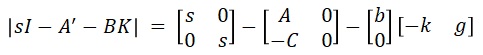
ここでA,B,Cを以下とします。こちらで説明したとおり。
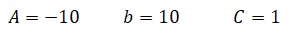
従って、
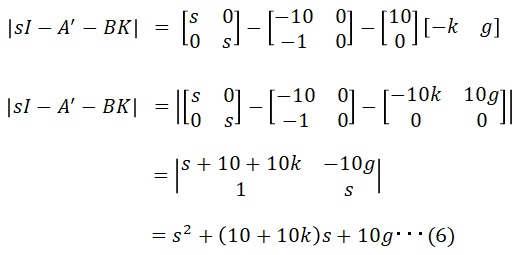
となり、特性方程式を求めることが出来ました。ここで特性方程式の根を自分で定めます。少なくても負である必要があります。
ここでは、-2の重根となるような、k,gの値を求めます。
k,gの求め方はテクニックがあり、先ず-2の重根を持つ方程式は以下となります。
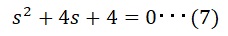
(6)と(7)を比較すると以下となり、k,gを求めることが出来ました。
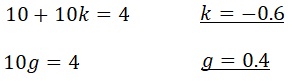
■Scilabでの設計
以下となります。
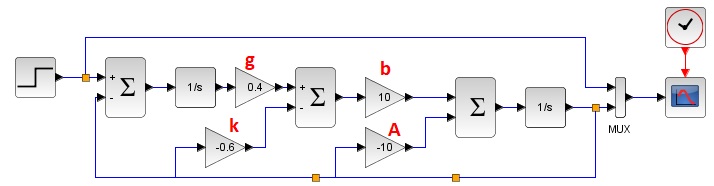
シミュレーション結果は以下のとおり。緑線に対して赤線は、劣化などの影響によりBの値が10⇒9に変わってしまった場合の結果です。
たとえ制御対象物の特性が変わったとしてもこの手法では目標値に追従させることが出来ます。

■内部モデル原理の有用性
内部モデル原理を使えば目標値に追従させることが出来ましたが、内部モデルを使わなかった場合どうなるのか説明します。以下の様に設計します。
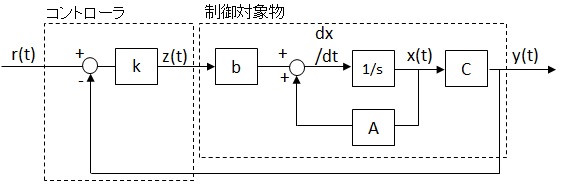
上記システムの微分方程式は、
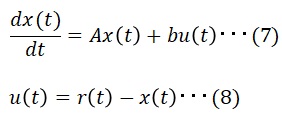
(8)を(7)に代入、ラプラス変換し、特性方程式を求めます。
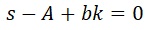
s=-2, A=10, b=10を代入。
■シミュレーション結果
以下の様に目標値に対して偏差をもって収束するのが解ります。
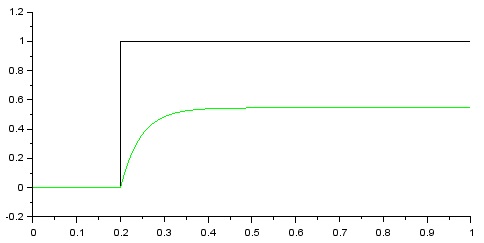
■目標値に収束しない理由
実はこの内部モデルを使わない形は、古典制御のP制御と等価の形(目標値との差分にゲインを掛ける)になっていることに気が付きます。
P制御が目標値に追従せずに定常偏差を残す理由は、最終値の定理によって証明できます。詳細はこちらを参照。
一方この内部モデルを使った形は、古典制御のI-P制御※と等価の形になっており、積分器をいれる事で目標値に追従できることが解ります。
※ I-P制御は比例先行型PI制御といい、類似形をこちらで説明しております。
サブチャンネルあります。⇒ 何かのお役に立てればと
|
|