青空文庫の本文をpythonで抽出する |
|||||||
・エンコード,デコード ・ハッシュ関数 ・暗号化の仕組み ・青空文庫の本文抽出 ・形態素解析 ・単語にIDを付与し辞書作成 ・Bag Of Words(BOW) ・Word2Vec ・画像フィルタ ・アフィン変換 ・スクレイピングとは ・webの画像ダウンロード ・malformed AAC bitstream |
前提知識
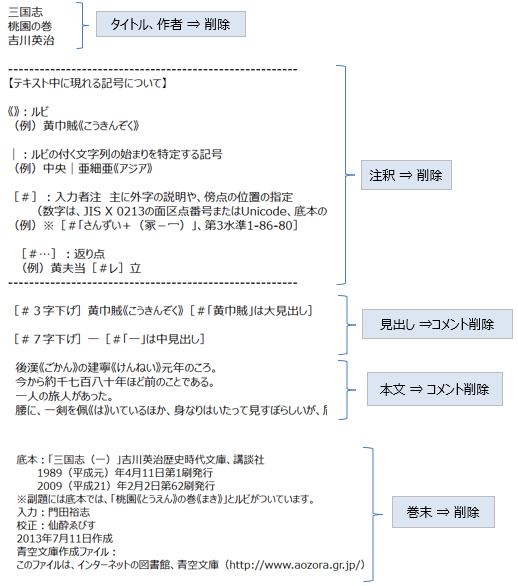
■青空文庫とは
import re
サブチャンネルあります。⇒ 何かのお役に立てればと
|
|
|||||